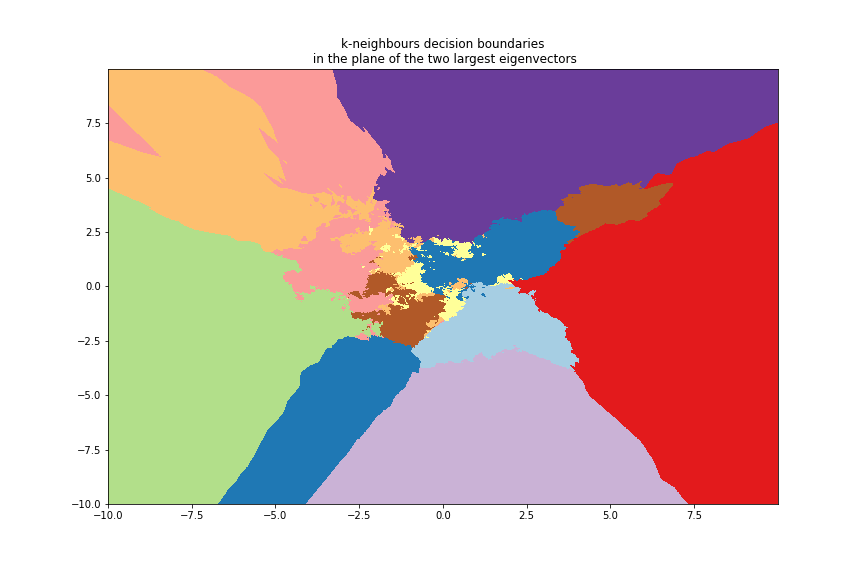
k-Neighbours¶
The $k$-neighbours method is an instance-based learning algorithm. It remembers the training set and when a new data point is presented it looks for the closest $k$ samples from the training set and returns
- the average of the target values of these $k$ values for regression
- the class of the majority of the $k$ training examples. (using some procedure to break ties)
Regularisation¶
The parameter $k$ can be used to control overfitting.
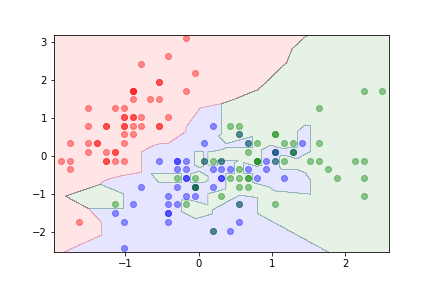
- With $k=1$ the algorithm is likely to overfit.
- Large values of $k$ can lead to underfitting.
Example¶
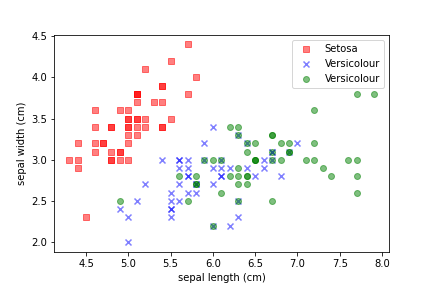
We can use the iris dataset:
k=1¶
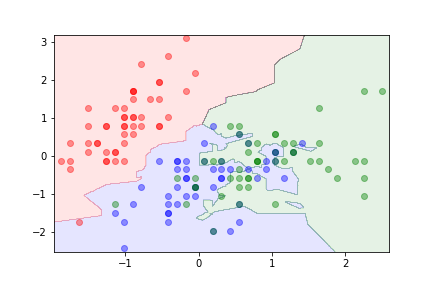
k =3¶
k=10¶
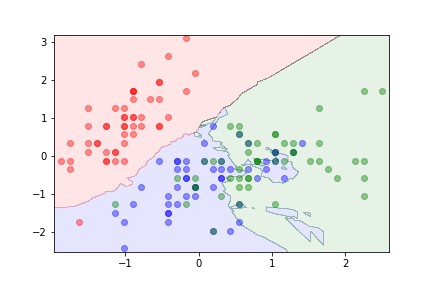
k=20¶
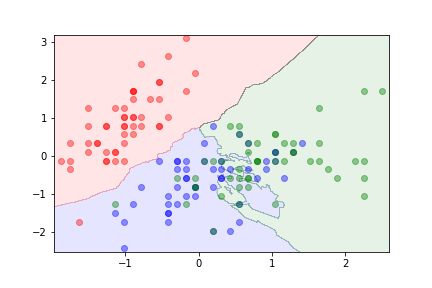
Digits example¶
We can use the 8x8 digits picture example after applying PCA to reduce it to 2 dimensions:
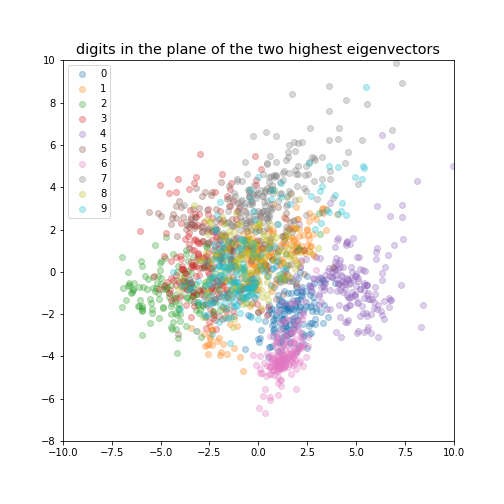
k=1¶

k=3¶

k=5¶

k=20¶