Logistic regression¶
The problems we had with the perceptron were:
- only converged for linearly separable problems
- stopped places that did not look like they would generalise well
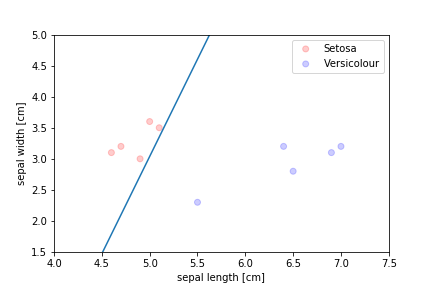
We need an algorithm that takes a more balanced approach:
- finds a "middle ground" decision boundary
- can make decisions even when the data is not separable
Logistic regression¶
- for binary classification for positive ($y=1$) vs negative ($y=0$) class
- for a probability $p$ to belong to the positive class, the odds ratio is given by $$ r=\frac{p}{1-p}$$
- if $r > 1$ we are more likely to be in the positive class
- if $r < 1$ we are more likely to be in the negative class
- to make it more symmetric we consider the log of $r$
- use a linear model for $z=log(r)$: $$ z= \omega_0 + \sum_j x_j w_j = w_0 + (x_1,...,x_D)\cdot (\omega_1,...,\omega_D) $$
If we set $x_0 = 1$ we can write this as
$$ z= \sum\limits_{j=0}^{n_f} x_j w_j = (x_0, x_1,...,x_D)\cdot (\omega_0, \omega_1,...,\omega_D) $$We can invert to obtain probability as a function of $z$ $$ p = \frac{1}{1+e^{-z}}\equiv \phi(z) $$
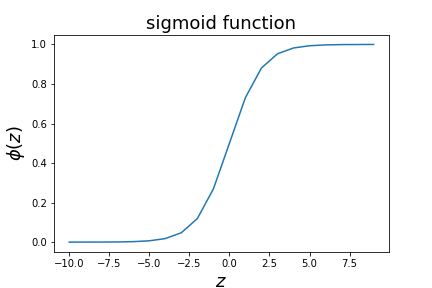
logistic regression optimisation¶
- the typicall loss function optimised for logistic regression is
- only one of the log terms is activated per training data point
- if $y^{(i)}=0$ the loss has a term $\log(1-\phi(z^{(i)}))$
- the contribution to the loss is small if $z^{(i)}$ is negative (assigned correctly)
- the contribution to the loss is large if $z^{(i)}$ is positive (assigned incorrectly)
- if $y^{(i)}=1$ the loss has a term $\log(\phi(z^{(i)}))$
- the contribution to the loss is large if $z^{(i)}$ is negative (assigned incorrectly)
- the contribution to the loss is large if $z^{(i)}$ is positive (assigned correctly)
- if $y^{(i)}=0$ the loss has a term $\log(1-\phi(z^{(i)}))$
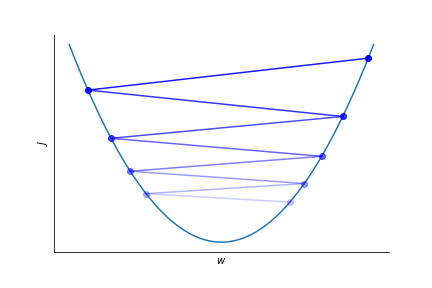
Gradient descent¶
To optimize the parameters $w$ in the logistic regression fit to the log of the probability we calculate the gradient of the loss function $J$ and go in opposite direction.
$$ w_{j} \rightarrow w_j -\eta \frac{\partial J}{\partial w_j} $$$\eta$ is the learning rate, it sets the speed at which the parameters are adapted.
It has to be set empirically.
Finding a suitable eta is not always easy.
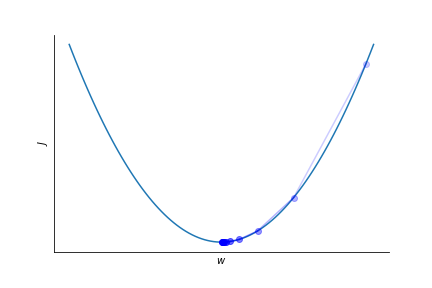
A too small learning rate leads to slow convergence.
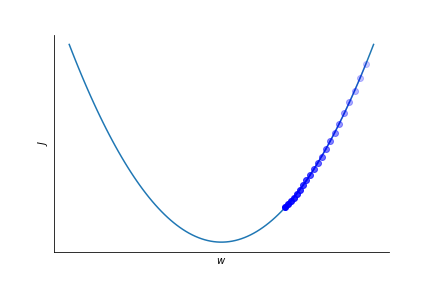
Too large learning rate might spoil convergence altogether!
Gradient descent for logistic regression¶
$$ \frac{\partial \phi(z)}{\partial z} = - \frac{1}{(1 + e^{-z})^2} (-e^{-z}) = \phi(z) \frac{e^{-z}}{1 + e^{-z}} = \phi(z) (1-\phi(z)) $$$$ \frac{\partial \phi}{\partial w_j} = \frac{\partial \phi(z)}{\partial z} \frac{\partial z}{\partial w_j} = \phi(z) (1-\phi(z)) x_j$$$$ \begin{eqnarray} \frac{\partial J}{\partial w_j} &=& - \sum_i y_i \frac{1}{\phi(z_i)}\frac{\partial \phi}{\partial w_j} - (1-y_i)\frac{1}{1-\phi(z_i)}\frac{\partial \phi}{\partial w_j} \\ &=& - \sum_i y_i (1-\phi(z_i))x_j^{(i)} - (1-y_i)\phi(z_i)x_j^{(i)} \\ & = & - \sum_i (y_i - \phi(z_i)) x_j^{(i)} \end{eqnarray} $$where $i$ runs over all data sample, $1\leq i \leq n_d$ and $j$ runs from 0 to $n_f$.
Loss minimization¶
Algorithms:
- gradient descent method
Newton method: second order method Training:
use all the training data to compute gradient
- use only part of the training data: Stochastic gradient descent
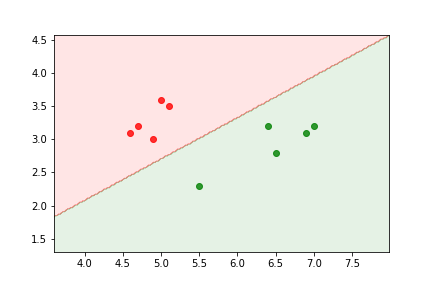
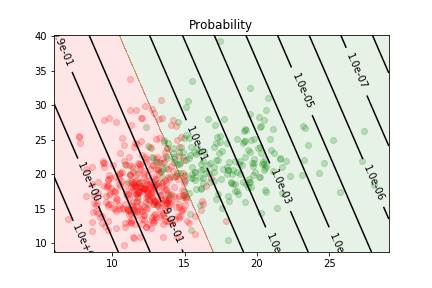
Logistic regression example¶
two features relevant to the discrimination of benign and malignent tumors:
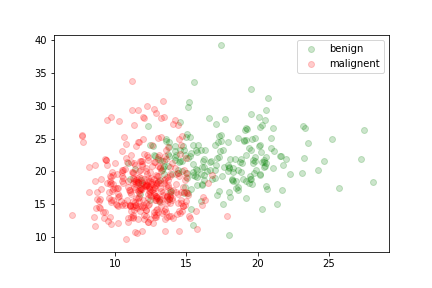
The data is not linearly separable.
We can train a sigmoid model to discriminate between the two types of tumors. It will assign the output class according to the value of
$$z= w_0 + \sum_j w_j x_j = w_0 + (x_1,x_2) (\omega_1,\omega_2)^T $$where $\omega_0$, $\omega_1$ and $\omega_2$ are chosen to minimize the loss.
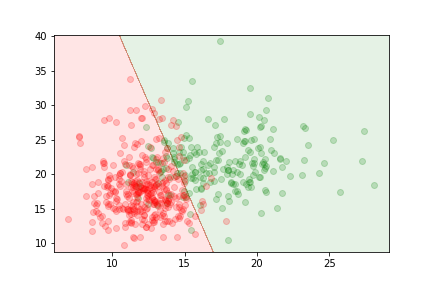
The delimitation is linear because the relationship between parameters and features in the model is linear.
The logistic regression gives us an estimate of the probability of an example to be in the first class
Normalising inputs¶
It is often important to normalise the features. We want the argument of the sigmoid function to be of order one.
- Too large or too small values push the problem into the "flat" parts of the function
- gradient is small
- convergence is slow
It is useful to normalise features such that their mean is 0 and their variance is 1.