Neural networks¶
Neutral networks started as an attempt to model the human brain. It is composed of neurones
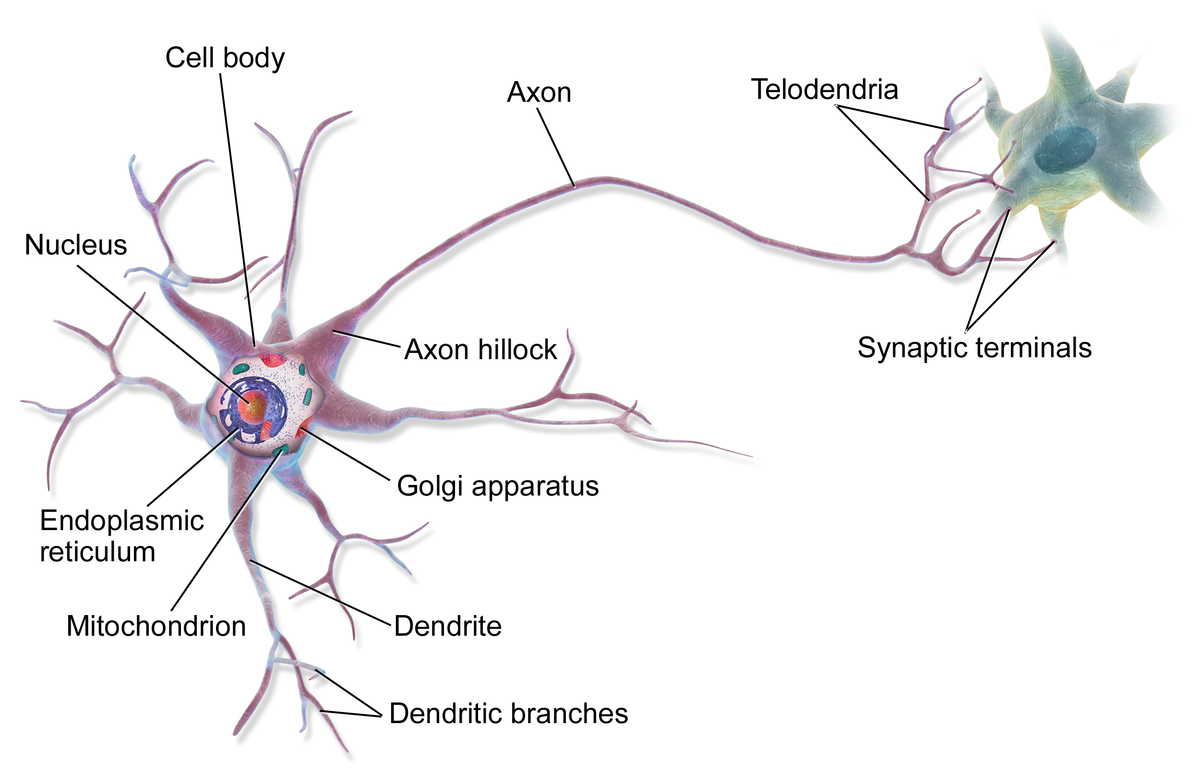
The model for a neuron was the perceptron:
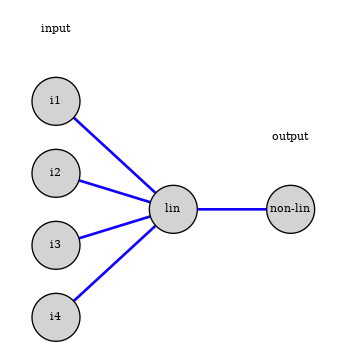
This is the model of a modern unit in a neural network:
- linear combination of inputs units
- non-linear function to generate the unit's value, called activation function
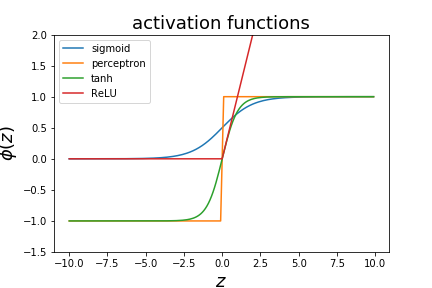
Non-linear activation functions¶
There are different decision functions that can be used.
- the perceptron used a step function
- logistic regression uses the sigmoid function
- one can also use $\phi(z)=tanh(z)$ as a decision function
- various variations on the hinge function (ReLU)
Network architectures¶
Neural networks are build by connecting artificial neurons together.
They can be used for classification or regression. Here we will consider the classification case.
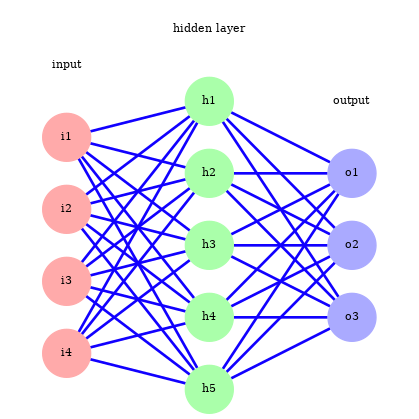
Single layer network¶
Multi layer network¶
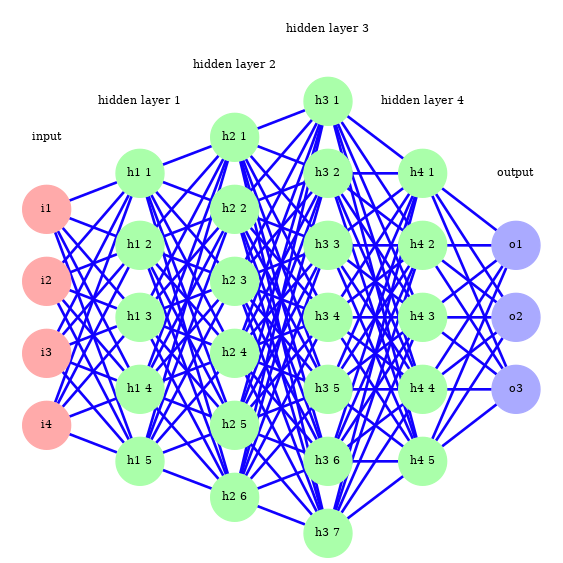
Networks with a large number of layers are referred to as "deep learning".
They are more difficult to train, recent advances in training algorithms and the use of GPUs have made them much tractable (and popular!).
Feedforward step¶
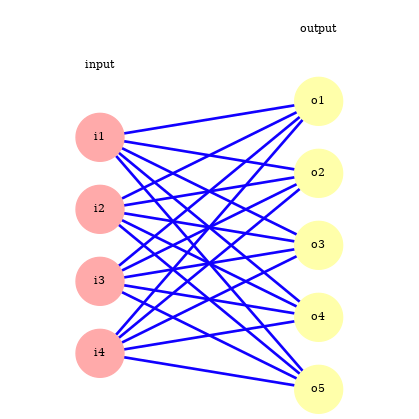
To calculate the output of the $j$-th unit for the $i$-th data example we calculate
$$o_j^{(i)} = \phi(z_j^{(i)}) \;,\qquad z_j^{(i)} = w_{0j} +\sum_{k=1}^{n_i}w_{kj}\cdot x^{(i)}_k$$If we have a $n_i$ input nodes and $n_o$ output units we have $(n_i+1)\times n_o$ parameters $w_{kj}$. We can organise them in a $n_i+1$ by $n_o$ matrix of parameters $W$ and write the vector of $z$ values for the $n_o$ output units as
$$ z = W^T x $$where $x$ is the column vector of input values with a $1$ added as the 0-th component.
The value $z$ is then passed through the non-linear function.
Last step¶
If we have more that 2 classes we want the last layer's output to be probabilities of belonging to one the the $k$ classes in the classifier. For this we replace the sigmoid function with the softmax function:
$$ s_i(z) = \frac{e^{z_i}}{\sum_{j=1}^k e^{z_j}} $$It is by definition normalised such that the sum adds to one and is the multi-class generalisation of the sigmoid function. $s_i$ is largest for the index $i$ with the largest $z_i$. The classifier prediction will typically be the class $i$ with the largest value $s_i$.
$$ \frac{\partial s_i}{\partial z_j} = \frac{- e^{z_i}e^{z_j} + \delta_{ij}e^{z_i}\sum_{l=1}^k e^{z_l} }{\left(\sum_{j=1}^k e^{z_j}\right)^2} = s_i \frac{- e^{z_j} + \delta_{ij}\sum_{l=1}^k e^{z_l} }{\sum_{j=1}^k e^{z_j}} = s_i\left(\delta_{ij}-s_j\right) $$Multi-class loss function¶
The generalistaion of the cross entropy loss for multiple class is given by
$$ J = -\sum_{i,j} y^{(i)}_{j} log(\hat y^{(i)}_{j}) $$where $y^{(i)}_{j}$ is $1$ if training sample $i$ is in class $j$, 0 otherwise.
This is called one-hot encoding. The derivative of the loss function with respect to one of the predictions is given by
$$ \frac{\partial J}{\partial \hat y^{(i)}_{j}} = - \frac{y^{(i)}_{j}}{\hat y^{(i)}_{j}}\,.$$Example¶
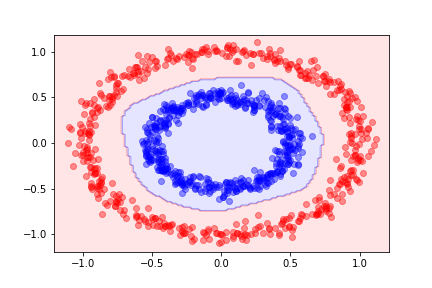
Using the same circle dataset that we used before, the decision function for a single-layer neural network with 10 hidden units gives the following decision boundary:
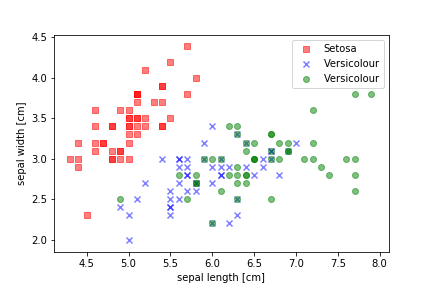
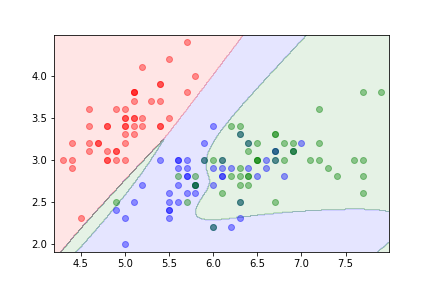
Here is an example using more than two classes.