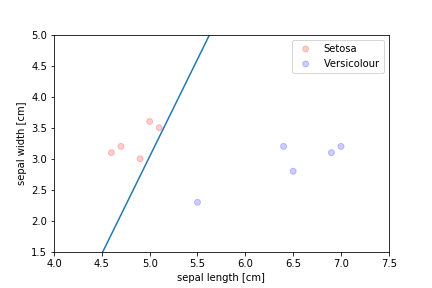
Perceptron¶
Perceptron algorithm was the first "Machine learning" algorithm
- invented in 1957 by Frank Rosenblatt
Classification¶
We have a set of examples of items from two classes. We want to train a model to distinguish between the two classes for new items.
Notation¶
Training data is composed of $n_d$ samples, each of which has $n_f$ features. Each data sample's class label is encoded as $\pm 1$.
$$\mbox{features: }\quad x^{(i)}_j,\qquad 1\leq i\leq n_d\,,\qquad 1\leq j \leq n_f $$ $$\mbox{labels: }\quad y^{(i)} = \pm 1\,,\qquad \qquad 1\leq i\leq n_d $$Model¶
We will train a linear model
$$ z(x, w) = w_0 + \sum_j x_j w_j $$with $n_f+1$ parameters
$$ w_j\,,\qquad 0 \leq j \leq n_f $$We will use the decision function
$$ \phi(z)= sgn(z) $$If $\phi(z)=+1$ our model predicts the object to belong to the first class, if $\phi(z)=-1$ the model predicts that the object belongs to the second class.
Now we need to set the parameters $w_j$ such that our pediction is as accurate as possible.
Perceptron Algorithm¶
Go through all the training data set and for each sample:
- calculate the prediction of the model with the current parameter
- if the prediction for $x^{(i)}$ is correct:
- move to the next sample
- if the prediction for $x^{(i)}$ is incorrect:
- adjust the parameter according to $$\begin{eqnarray}w_j &\rightarrow& w_j + \eta y^{(i)} x^{(i)}_j\,,\quad 1\leq j \leq n_f \\ w_0 &\rightarrow& w_0 + \eta y^{(i)}\end{eqnarray}$$
- move to the next sample
Repeat the procedure until no more examples are wrongly predicted (or until a small enough amount fails)
Each repeat is called an epoch.
Some references give the perceptron algorithm with a fixed value of $\eta$.
It is convenient to add a $1$ as the 0-th component of the data vector $x$
$$\vec{x} = 1, x_1, ... , x_{n_f}$$so that the linear model can be written as
$$ z(x,w) = \vec{x}\cdot \vec{w} $$This allows to write the update rule for the perceptron algorithm as
$$ \vec{w} \rightarrow \vec{w} + \eta\, y^{(i)}\, \vec{x}^{(i)} $$Learning rate¶
The parameter $\eta$ in the update rule
$$\begin{eqnarray}w_j &\rightarrow& w_j + \eta y^{(i)} x^{(i)}_j\,,\quad 1\leq j \leq n_f \\ w_0 &\rightarrow& w_0 + \eta y^{(i)}\end{eqnarray}$$is a parameter of the algorithm, not a parameter of the model or of the problem. It is an example or hyperparameter of a learning algorithm.
The learning rate set how much a single misclassification should affect our parameters.
- a too large learning rate will lead to the paramters "jumping" around their best values and give slow convergence
- a too small learning rate will make more continuous updates but it might take many epochs to get to the right values
Convergence¶
The perceptron algorithm is converging if the classes are linearly separable in the training set.
It might take a long time to converge
Linearly separable¶
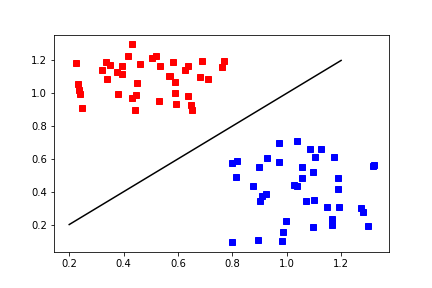
Separable, but not linearly¶
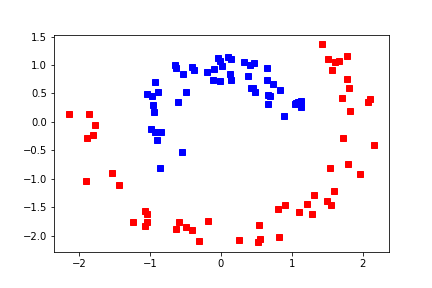
Probably not separable¶
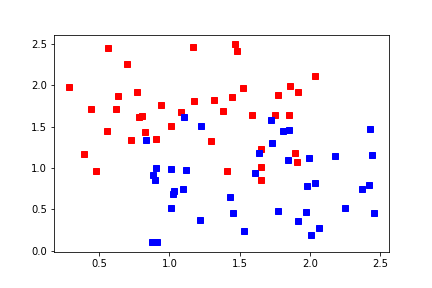
Problems with the perceptron algorithm¶
- convergence depends on order of data
- random shuffles
- bad generalisation
Bad generalisation¶
The algorithm stops when there is no errors left but often the demarcation line ends up very close to some of the instances, which leads to bad generalisation